Aller au contenu principal
axe7.labex-efl.org
Menu principal
Accueil
Description of Axe 7
EM1
EM2
EM3
EM4
Labex
Labex Seminars
Modélisation diasystémique et typologie
Seminar Joan Bresnan
Connexion utilisateur
Nom d'utilisateur
*
Mot de passe
*
Demander un nouveau mot de passe
General information
EM1 : The epistemological status of empirical data data in linguistics
EM2: Cross-mediated endangered language elicitation
EM3: Development of new protocols and methodologies
EM4: Maintaining and mutualizing existing platforms, installing new platforms
Prosopopeya (DA) en uru Werki parinćha
Soumis par
Karla Aviles
le ven, 11/29/2019 - 15:16
Lire la suite
de Prosopopeya (DA) en uru Werki parinćha
Identifiez-vous
pour poster des commentaires
Prosopopeya (DA) en uru Wejrki xwalthćha
Soumis par
Karla Aviles
le ven, 11/29/2019 - 15:04
Lire la suite
de Prosopopeya (DA) en uru Wejrki xwalthćha
Identifiez-vous
pour poster des commentaires
Prosopopeyas (DA) en bésiro Nutakónxi y en quechua Khirkinchu
Soumis par
Karla Aviles
le ven, 11/29/2019 - 14:54
Lire la suite
de Prosopopeyas (DA) en bésiro Nutakónxi y en quechua Khirkinchu
Identifiez-vous
pour poster des commentaires
Prosopopeyas (DA) en aymara Wari y en quechua Wikuña
Soumis par
Karla Aviles
le ven, 11/29/2019 - 14:46
Lire la suite
de Prosopopeyas (DA) en aymara Wari y en quechua Wikuña
Identifiez-vous
pour poster des commentaires
Prosopopeya (DA) en quechua Atuq
Soumis par
Karla Aviles
le ven, 11/29/2019 - 14:29
Lire la suite
de Prosopopeya (DA) en quechua Atuq
Identifiez-vous
pour poster des commentaires
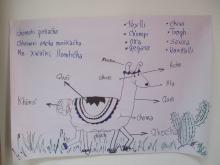
quichwa Chiwanku
Soumis par
Karla Aviles
le ven, 11/29/2019 - 14:23
Prosopopeya en quichwa:
Chiwanku.
Lire la suite
de quichwa Chiwanku
Identifiez-vous
pour poster des commentaires
Prosopopeyas en lenguas originarias (Cochabamba 2019)
Soumis par
Karla Aviles
le ven, 11/29/2019 - 14:13
Prosopopeyas (Descripción de Animales) en lenguas originarias.
Lire la suite
de Prosopopeyas en lenguas originarias (Cochabamba 2019)
Identifiez-vous
pour poster des commentaires
Cochabamba (Bolivia, 2019)
Soumis par
Karla Aviles
le ven, 11/29/2019 - 12:13
Taller de elaboración de recursos pedagógicos en lenguas originarias realizado en la Facultad de Humanidades y Ciencias de la Educación de la UMSS, con el apoyo del FUNPROEIB Andes.
Mesas de trabajo:
-
Prosopopeyas (Descripción de animales)
-Comunidades invisibles, comunidades imaginadas (utopías / distopías)
Lire la suite
de Cochabamba (Bolivia, 2019)
Identifiez-vous
pour poster des commentaires
Talleres / Ateliers / Workshops 2019
Soumis par
Karla Aviles
le ven, 11/29/2019 - 12:03
-
Cochabamba (Bolivia)
Lire la suite
de Talleres / Ateliers / Workshops 2019
Identifiez-vous
pour poster des commentaires
Isoglosas y variantes zoques
Soumis par
Karla Aviles
le mar, 11/12/2019 - 11:27
Isoglosas y variantes zoques de Tapalapa, de Chapultenango (ambos en Chiapas), de Uxpanapa y de Las Choapas (Veracruz).
Lire la suite
de Isoglosas y variantes zoques
Identifiez-vous
pour poster des commentaires
Pages
1
2
3
4
5
6
7
8
9
…
suivant ›
dernier »
EM1
news
Paul Broca (lien externe)
seminaire empiricité (lien externe)
école d'été
EM2
bilan scientifique
ateliers/workshops
elicitaciones / elicitations
EM3
news
eye tracking glasses
EM4
news
heures de consultations
resources
statistics
summer school 2013